lmage + Text or Video + Text Query

lmage or Video Query
Text Query
Existing multimodal video retrieval systems are limited by weak intent understanding and rigid similarity-based matching, especially when handling composed queries that integrate heterogeneous inputs.
To fill this gap, we propose ViRe-Agent, a retrieval agent that formulates multimodal search as a policy-driven decision process. The core contribution lies in a Light MDP routing mechanism, which selects an optimal retrieval policy (semantic, similarity, composed, or fingerprint-based) conditioned on both query intent and segment-level video semantics.
We further integrate scene segmentation and multi-modal fingerprinting to support cross-duration queries and provenance tracing. Extensive experiments demonstrate consistent improvements over recent baselines including CoVR, TransVCL, and CLIP4Clip, with gains up to 4.6% R@1 on real-world data.
ViRe-Agent operates under two distinct modes: Feature Extraction Mode and Retrieval Mode. The system integrates multimodal input parsing, LLM-based intent understanding, and dynamic retrieval strategy selection.
Figure 1: The overall architecture of the multi-modal video retrieval agent system.
The core of our agent is the Light MDP routing mechanism. It selects the optimal retrieval policy (Semantic, Similarity, Composed, or Fingerprint) conditioned on query intent and current states.
Figure 2: The decision-making workflow of the ViRe-Agent.
We perform semantic scene segmentation on the original long video based on TransNetV2. Shot transition detection and clustering semantic coherence shots into segments allows for fine-grained retrieval.
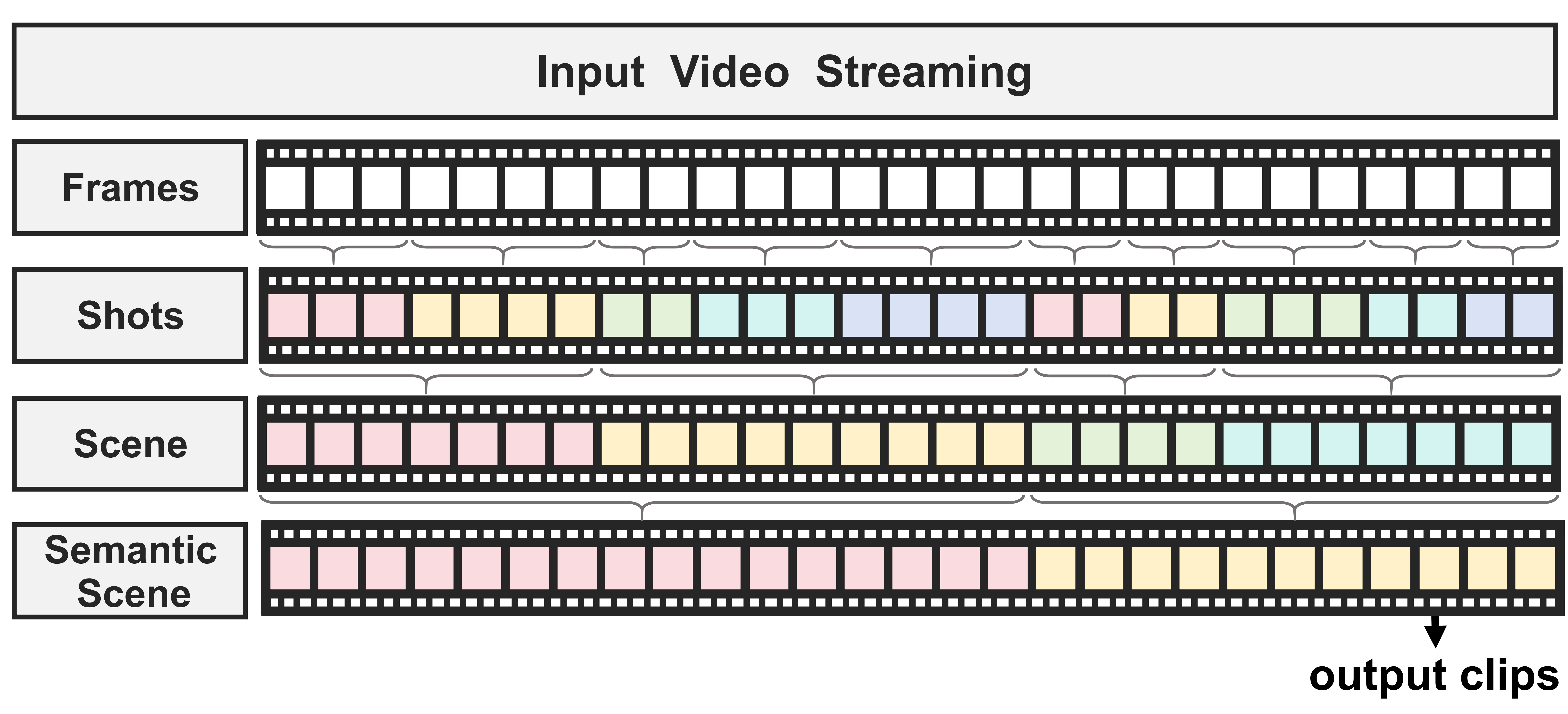
Figure 3: Semantic scene segmentation pipeline.
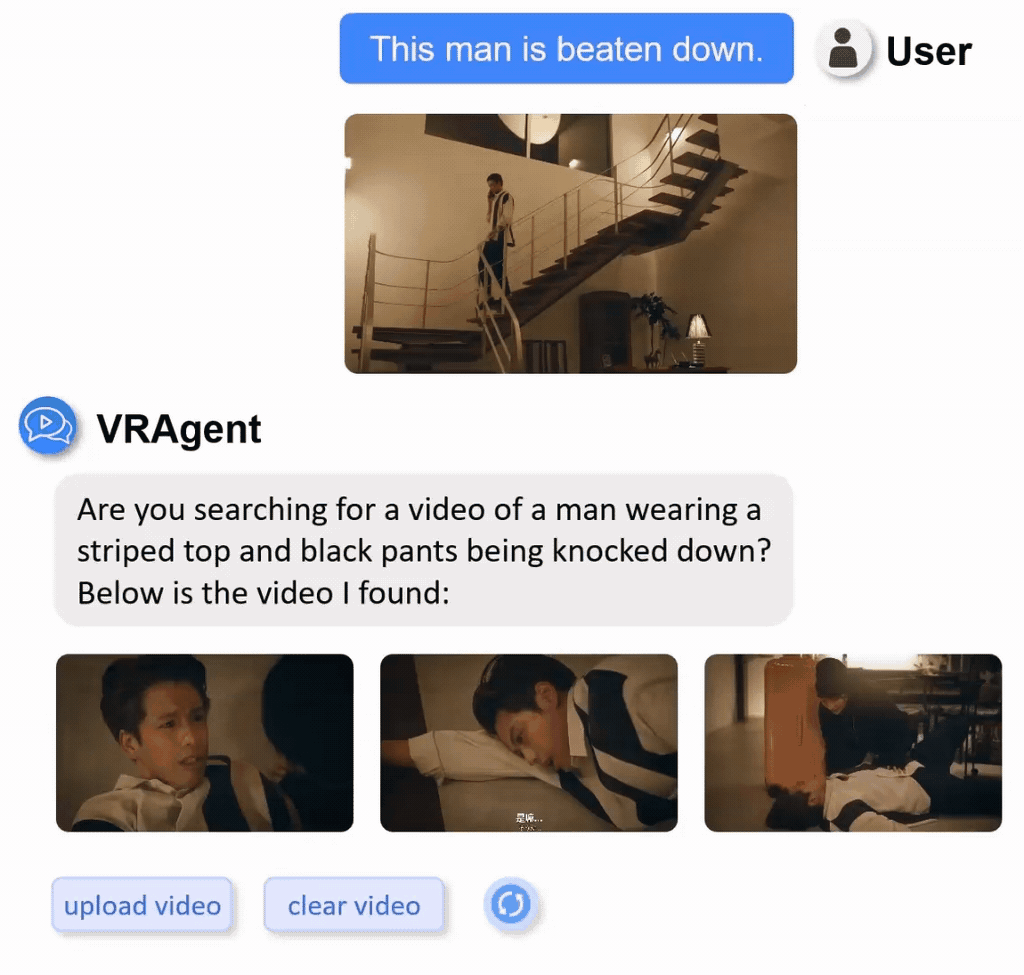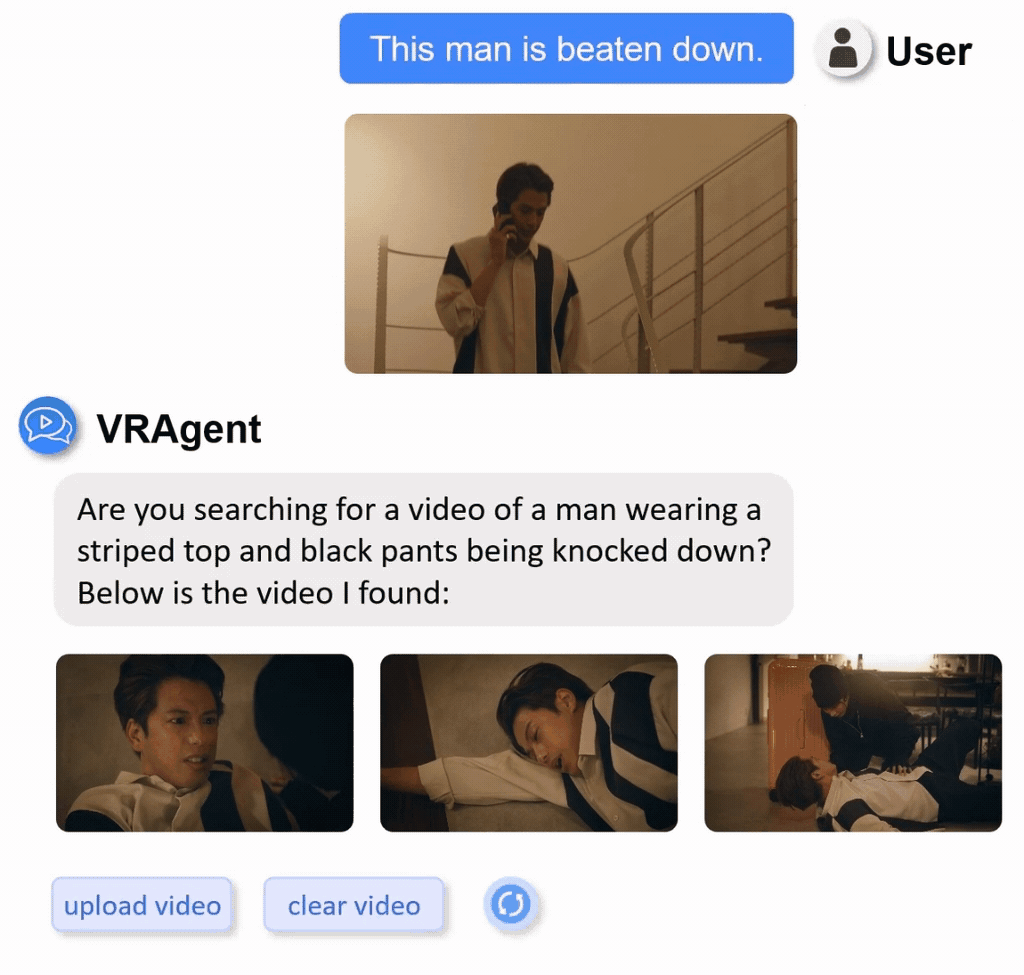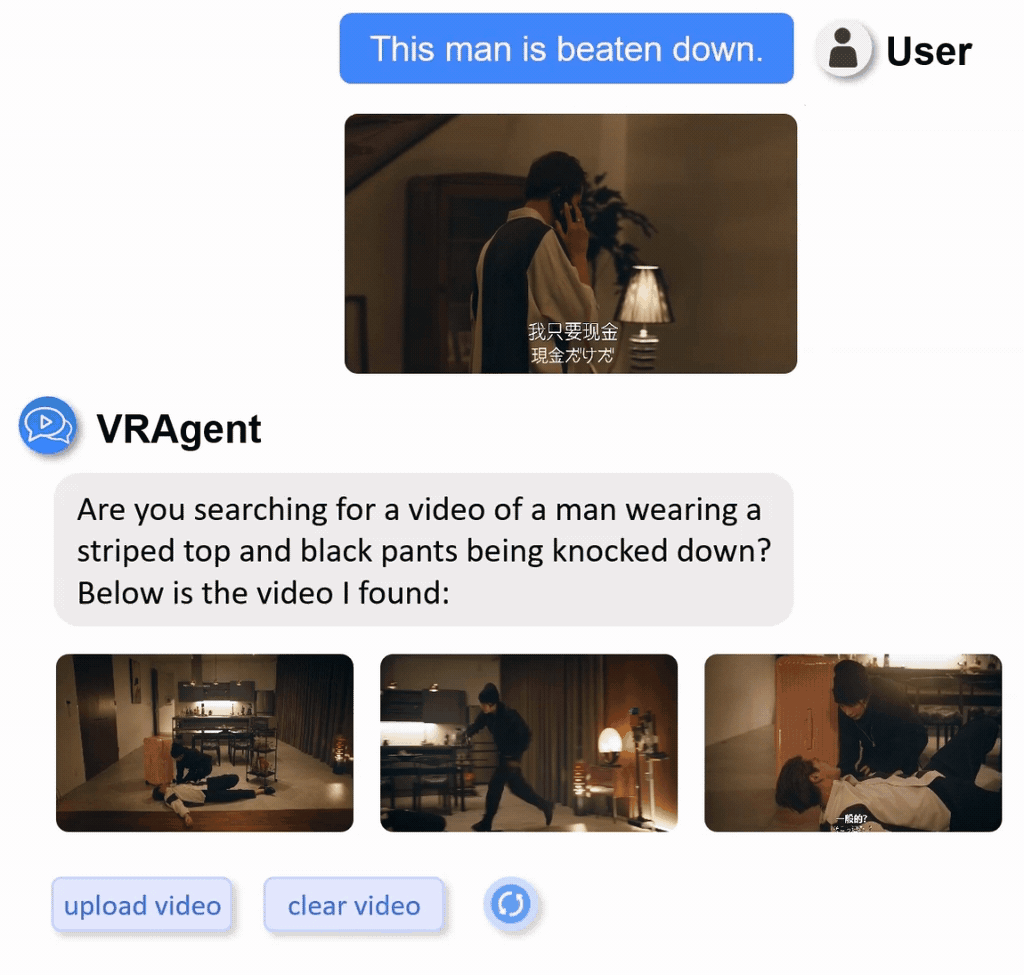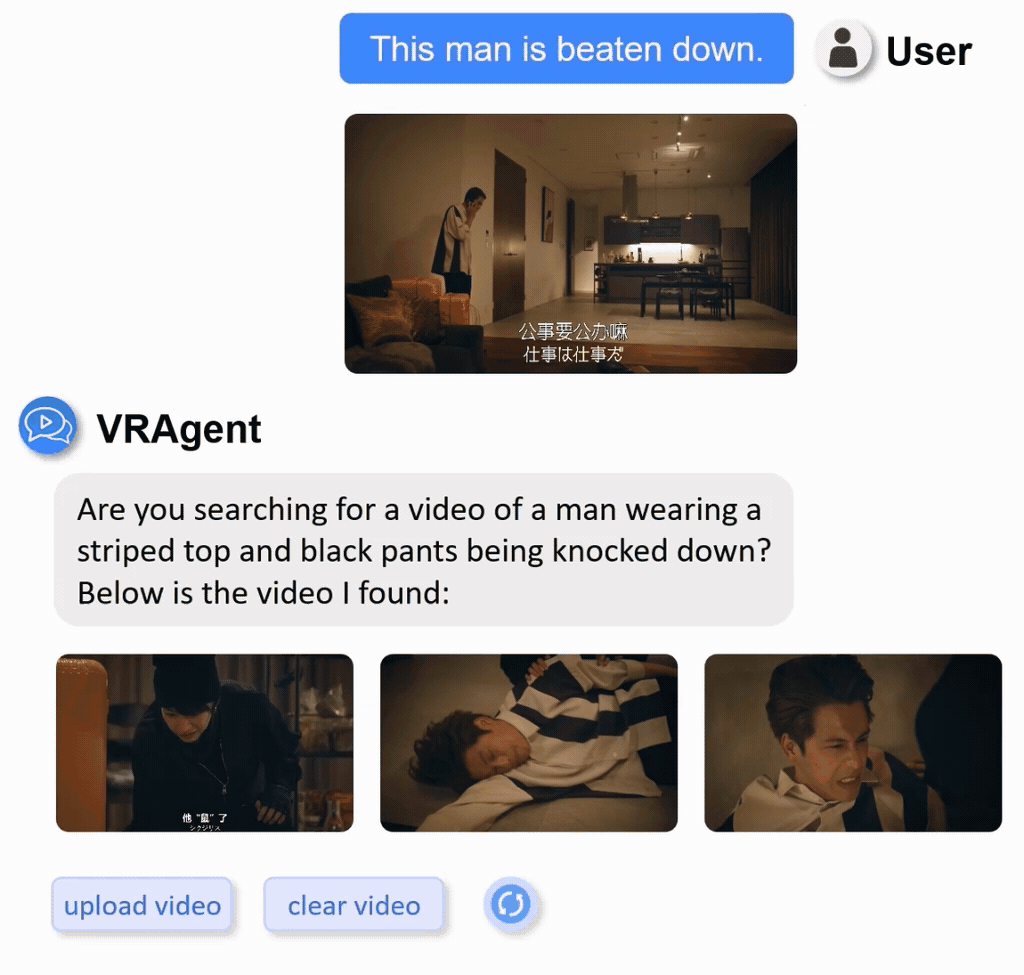
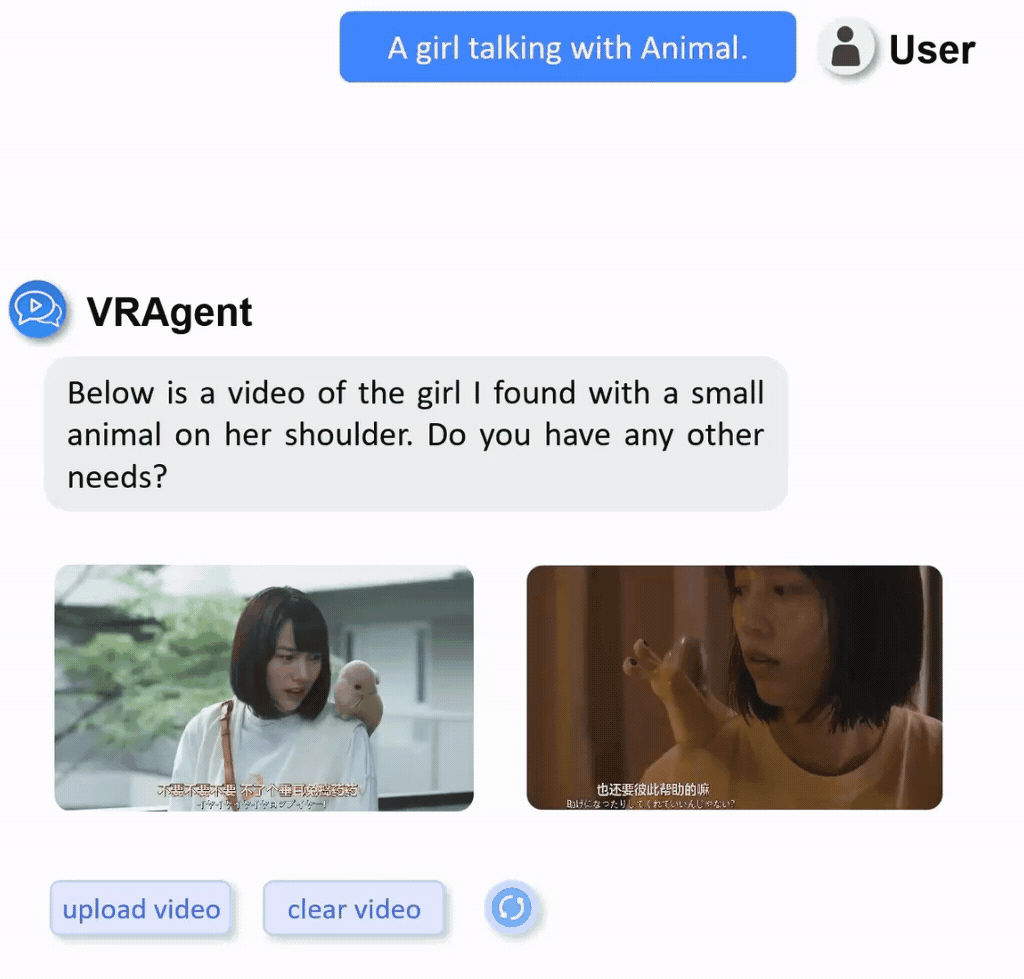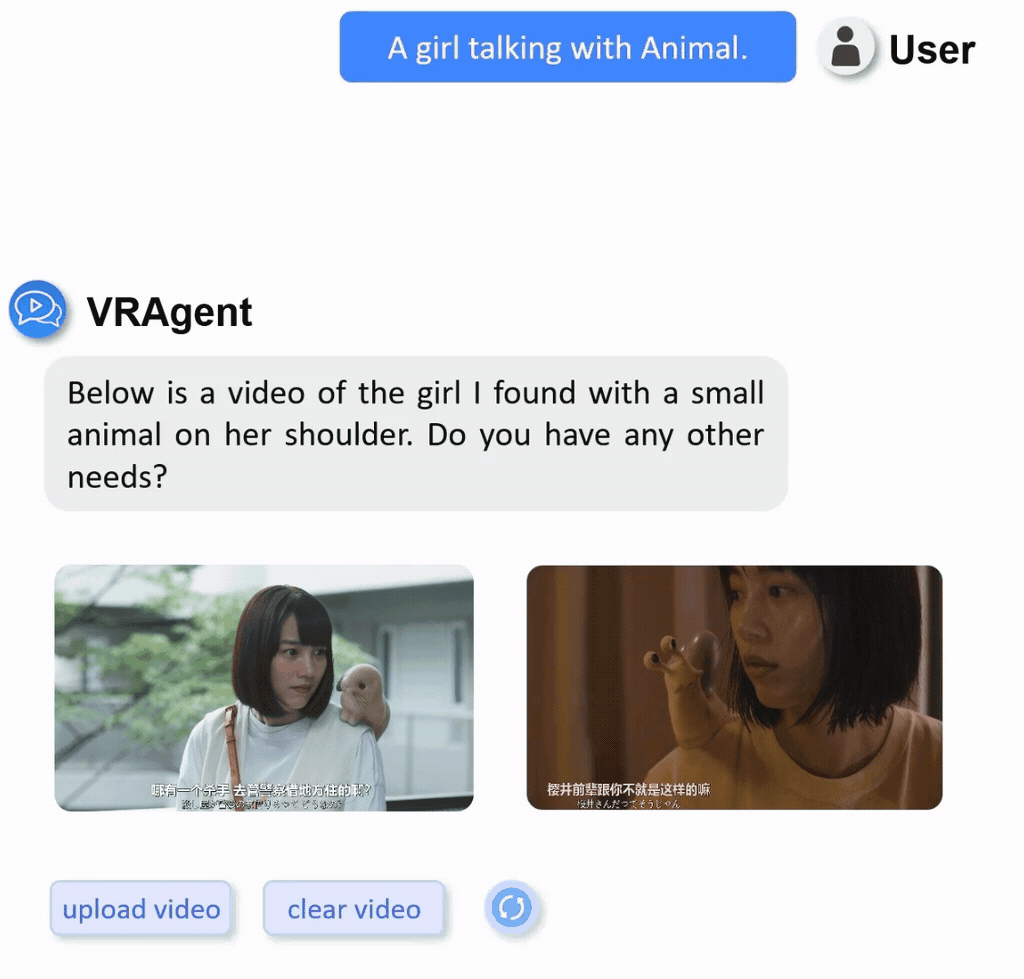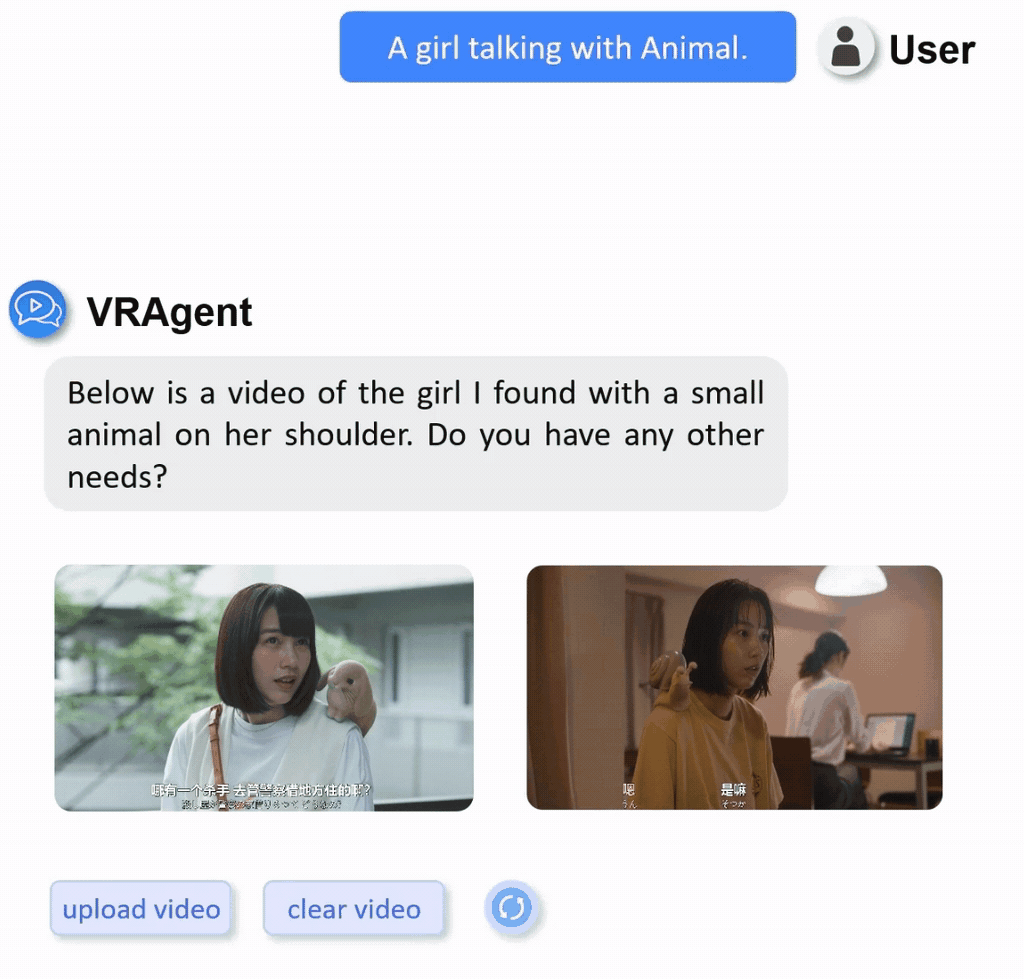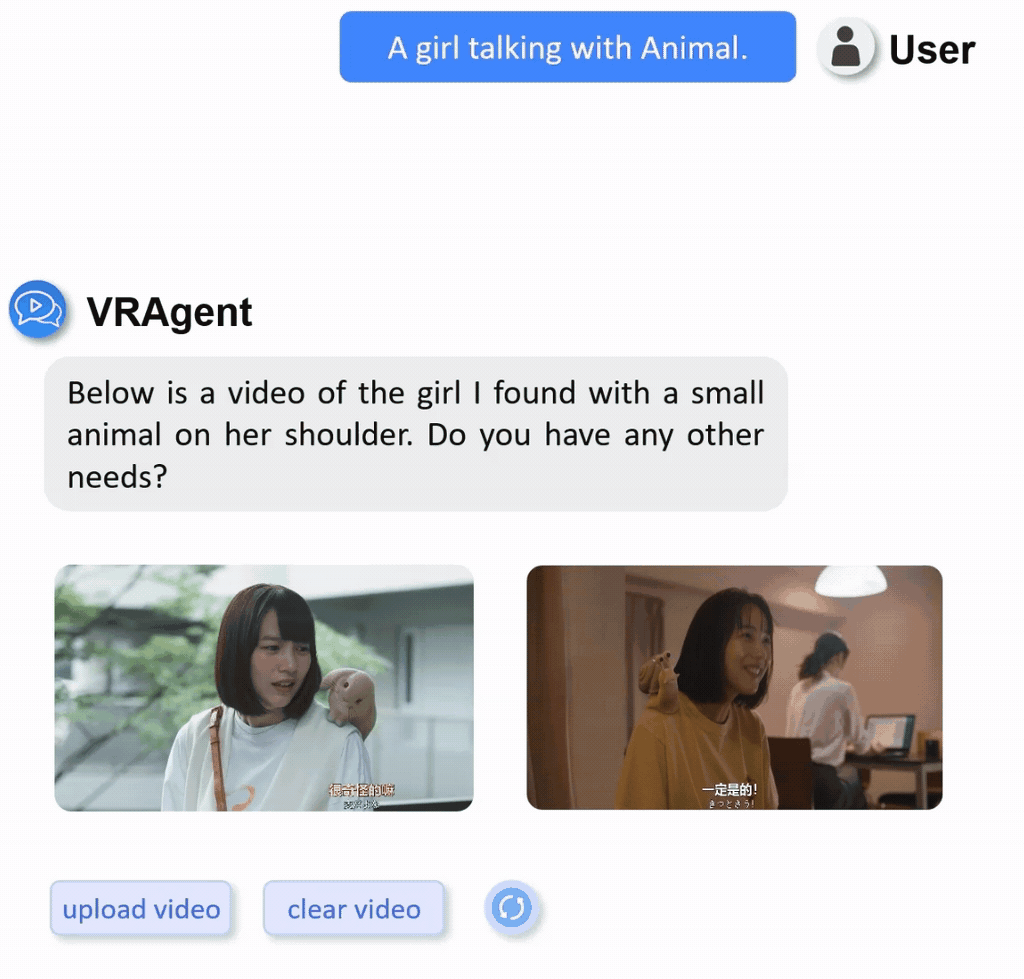
We constructed a real-world video retrieval dataset (R3V) comprising 1,000 clips sourced from diverse content including films, TV dramas, documentaries, and variety shows.

Display of part of real-word private dataset with multilingual annotations.
Notice
Placeholder